
Authors: Dr. Lourival Carmo Monaco Neto, Postdoctoral Research Associate
Dr. Allan W. Gray, Executive Director and Professor
In previous articles in this series (Data-Driven Decision Making in Times of Crisis, and What Data?), we discussed how data and information are crucial for more informed decision making and how the transformation of data and information into intelligence is what leads to this concept of informed decision making. We also discussed how understanding the specific intelligence needs of a decision maker and tracing back to critical data needs is the best strategy to create a more efficient and effective intelligence process.
This article examines the act of collecting, organizing and storing selected data and information that has been identified as needed. The objective is to create a process that allows for timely availability of the most relevant data for transformation into intelligence. The following framework is a simple guide for actions taken to collect such data.
Data and Information Collection, Organization and Storage Framework
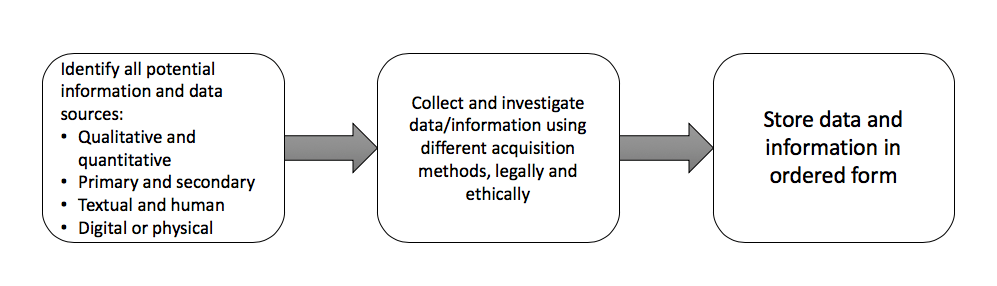
The first step is identifying potential sources of the desired data and information. These sources can include people, objects (products or components), records (literature), and so on. Many of these information sources can be found online through search engines, news groups such as commercial news organizations or informal news and discussion groups, and more. The critical task to complete is thinking of all possible places information may be found. The data collection function rests on research that matches validated intelligence needs to available sources of information.
Think of the numerous sources of information being mentioned since the onset of COVID-19. A myriad of data from a variety of sources is presented each day. Even in situations where a decision maker knows what data is necessary to collect, looking for information in the wrong places can lead to dead ends or incorrect data that can cause potentially poor decisions. All crisis scenario present decision makers with this challenge, demanding a disciplined approach to avoid poor decisions.
An important element of data is whether it is obtained from primary or secondary sources. Primary sources of data come straight from the originator without transformation or interpretation. These sources include company internal knowledge provided by its personnel and other collaborators (input suppliers, competitors, distribution channels, etc.), direct collection of data and information from the intelligence team through the use of interviews, surveys, tabulations, and so on. Primary sourced data is valuable and credible as it is collected directly for its intended use in the intelligence process. However, primary data is also quite expensive to collect and often suffers from timeliness constraints, as well as errors in collection processes.
Primary sourced data is particularly important for agribusiness companies as it can help them to understand how farmers feel about the products they use, what brands they are likely to purchase and many more behavioral aspects. This type of data/information has unlimited applications for companies, such as segmenting customer bases, preparing communication campaigns, developing overall marketing strategies, and more. Intelligence needs requiring this type of information can find primary data sources extremely helpful in collecting appropriate data to meet these needs.
Additionally, the proliferation of internet-based information such as the Internet of things and big data make this type of data source even more relevant for agribusiness companies. For example, think about the amount of information a harvester can generate. This primary data/information is extremely valuable to those who can use it; however, having the resources (in this case, the data itself) and the capabilities to take full advantage of this technology is one of the many challenges of any data related effort.
On the other hand, secondary sources interpret and analyze primary sources. While a primary source passes direct knowledge of an event on to the analyst, a secondary source provides information twice removed from the original event. One observer informs another, who then relays the account to the analyst. Such regression of source proximity may continue indefinitely. Naturally, the more numerous the steps between the information and the source, the greater the opportunity for error or distortion.
Secondary sources may contain pictures, quotes or graphics of primary sources. These data sources are also important and are usually easier and more efficient to access; however, because this data is not directly collected by the user, it can be difficult to guarantee the data’s integrity. As such, users must spend time determining the original collector’s method, intended use for the data and any transformation processes before using the data for their own purposes.
Beyond determining the sources of data, there are many useful tools to assist in searching for required information. These tools can be separated into two categories:
- Active collection tools: Active collection tools support searches through the development of search terminology and intelligently categorizing results (also known as informational pull). These tools survey knowledge domains and target specific questions. Examples are web search engines such as Google or an interview with a specialist.
- Passive collection tools: Passive collection tools are directed at supporting ongoing informational needs. It is common for decision makers and intelligence professionals to utilize software agents to provide daily updates on news, competitor activities and changes to competitor web sites (also known as informational push). Formulas and algorithms that constantly search for this kind of information are often used for this purpose, usually in conjunction with visualization tools.
Finally, after the data is acquired, it is fundamental to organize and store it for easy access and utilization when needed. Depending on the size and scope of the data collected, it can be stored in something as simple as an Excel spreadsheet. For larger, more complex and/or multidimensional data sets, an investment in specialized hardware and software may be required.
Although data is often referenced as a modern world form of currency, hoarding data mindlessly greatly destroys its inherent value. Being able to find and access specific data in timely and efficient fashion is as important as collecting it. Thus, indexing data within a database is fundamental to the intelligence effort’s efficiency. Indexes are used to efficiently locate data without having to search every row in a database table each time it is accessed. Indexes can be created using one or more columns of a database table, providing the basis for both rapid random lookups and efficient access of ordered records. An index is a copy of selected columns of data from a table called a database key or simply key that can be searched efficiently. It also includes a low-level disk block address or direct link to the complete row of data it was copied from.
For example, consider the index of a book. Index entries consist of key words and page numbers. The key words are listed in alphabetical order, making it easy to searching for what we are interested in. We simply reference the index, look for the key word, find the entry, note the page number and flip to said page.
With the completion of data storage and organization, the collection is finished; however, the creation of intelligence is only just beginning. All that has been done up to this point has been preparation for the actual intelligence transformation. The analysis phase — the next step in the intelligence journey and arguably the most important — will be the focus of the next article in this series.


